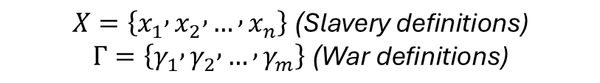(CD)ISaW addresses a persistent infrastructural gap in slavery and conflict studies: the absence of any unified, computationally queryable environment spanning the full typological and temporal range of slavery-in-war phenomena. Historical atrocity data is fragmented across incompatible formats, institutional repositories, and disciplinary silos; existing tools treat spatial, temporal, typological, and actor dimensions in isolation.
(CD)ISaW brings these dimensions together through a five-layer ontological architecture — Classification, Temporal, Spatial, Actors, and Conflict Events — and exposes them through a researcher-facing 4-step query wizard and a fully documented REST API. The platform is designed as both a research instrument and a reusable infrastructure template, enabling systematic, reproducible cross-source queries that would otherwise require bespoke scripting for every research question.
Research Context
The scholarly study of slavery in war draws on evidence from armed conflict databases (ACLED, UCDP, ICTY case records), humanitarian datasets (UNHCR displacement data, ILO forced labour surveys), archival sources, and qualitative case studies. These sources differ in format (REST APIs, CSV exports, GeoJSON, SQLite archives, SPARQL endpoints), temporal resolution (year-level to day-level), geographic reference frame, and disciplinary vocabulary.
This heterogeneity is not incidental — it reflects the genuinely multi-disciplinary nature of the field. But it creates a structural obstacle: researchers who wish to compare patterns of forced labour across civil wars, or to trace the spatial distribution of sexual slavery during colonial conflicts, must manually assemble and reconcile data from sources that were never designed to be used together.
(CD)ISaW was conceived as a solution to this problem: not a new dataset, but a generalising infrastructure layer — a platform that can ingest and normalise existing sources while providing a consistent query interface and a shared ontological framework through which heterogeneous evidence can be compared, combined, and cited reproducibly. The platform is anchored by the Leverhulme Centre for Research on Slavery in War at the University of Nottingham’s Rights Lab, whose Forecasting strand requires exactly this kind of cross-source analytical infrastructure.
Five-Layer Ontology
Every record in (CD)ISaW is structured across five interdependent layers. This is not a flat schema — it is an ontological commitment about how slavery-in-war evidence is meaningfully constituted.
Layer 0 — Classification Matrix
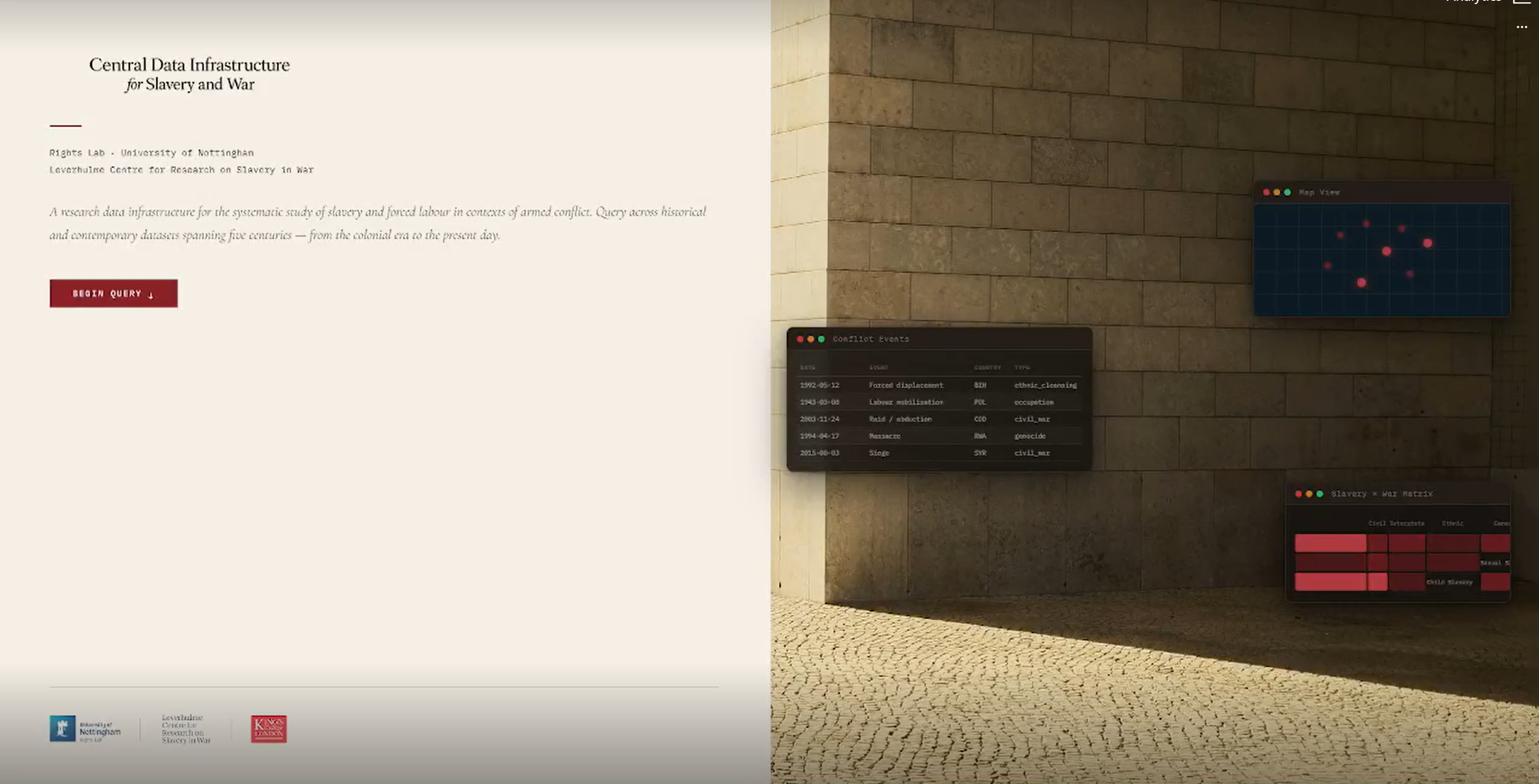
The foundational layer. Every dataset receives an assignment within a 10 × 11 slavery × conflict typology grid, mapping across slavery typologies (chattel slavery, debt bondage, forced labour, forced marriage, child slavery, sexual slavery, domestic servitude, state-imposed labour, serfdom) against conflict contexts (interstate war, civil war, colonial conflict, occupation, genocide, ethnic cleansing, insurgency, terrorism, peacekeeping context, post-conflict). A dataset can be assigned to any combination of cells simultaneously. This matrix is the primary entry point for the query interface: researchers define their research question by selecting which cells they are interested in before applying any other filter.
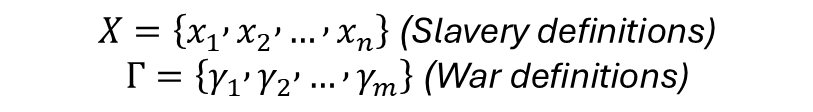
Layer 1 — Temporal
Temporal corpus spanning 1700-01-01 to present, with variable precision (year, month, or day), support for circa dates and ranges, stored as PostgreSQL DATE with a precision flag column. Research questions anchored to specific historical periods — the Transatlantic Slave Trade (1600–1870), the Bosnian War (1992–1995) — are expressed as first-class query constraints rather than post-hoc filters.
Layer 2 — Spatial (H3)
Global H3 hexagonal indexing (Uber H3) at resolutions 0–15, stored as TEXT alongside PostGIS geometry(Point, 4326). Spatial lookup by H3 index, lat/lng coordinates, or ISO admin0/admin1/admin2 codes; bounding-box filtering via PostGIS ST_Within. The use of H3 reflects a methodological commitment across the lab’s spatial research: hexagons provide uniform area, hierarchical aggregation, and cross-language reproducibility.
Layer 3 — Actors
Actor types spanning individual, armed group, state, paramilitary, criminal network, NGO, international organisation, corporation, and unknown. Name variant and alias support via pg_trgm fuzzy search, external ID linking to Wikidata QIDs, ACLED actor IDs, and ICTY case references, with a role vocabulary covering perpetrator, victim, state authority, witness, and rescuer. The actor layer enables network-style queries — tracing how specific individuals, groups, or state entities appear across multiple events, datasets, and time periods.
Layer 4 — Conflict Events
Event categories including battle, siege, massacre, forced displacement, raid/abduction, labour mobilisation, liberation/escape, treaty/ceasefire, atrocity, and resistance. Each event cross-references layers 1, 2, and 3 in a single record, with fatality and enslaved population estimate ranges and a raw JSONB column preserving original source fields alongside normalised columns.
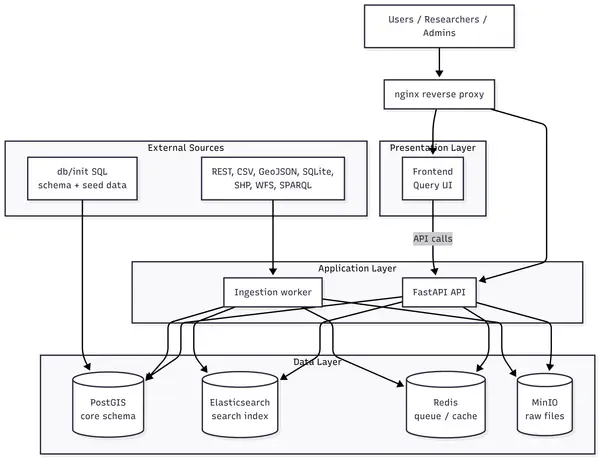
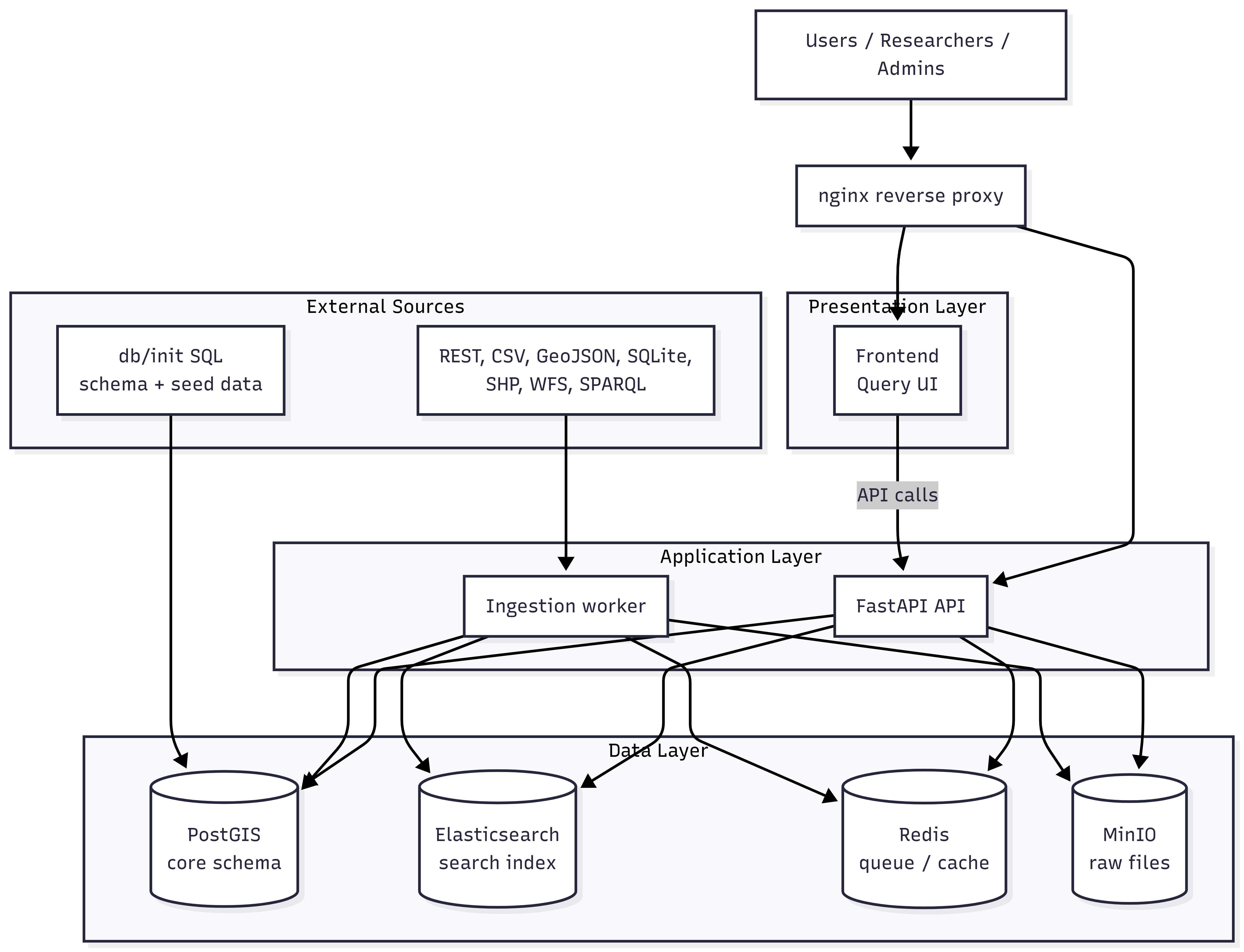
Infrastructure Architecture
Eight Docker containers form two logical clusters — a query cluster (nginx, frontend, FastAPI, PostgreSQL/PostGIS, Elasticsearch, Redis) and an ingestion cluster (worker, MinIO object storage).
| Layer | Technology | Version |
|---|---|---|
| API | FastAPI + asyncpg | Python 3.12 |
| Database | PostgreSQL + PostGIS | 16 |
| Search | Elasticsearch | 8.13 |
| Cache / Queue | Redis | 7 |
| Object storage | MinIO | RELEASE.2024 |
| Frontend | Vanilla JS + MapLibre GL | — |
| Spatial indexing | H3 (Uber) | 4.x |
| Proxy | nginx | alpine |
| Containerisation | Docker Compose | v2 |
Connector System
Datasets are registered with a connector configuration — a declarative specification of how to ingest the source and map its fields onto the (CD)ISaW layer schema. This separates the act of describing a source (registration) from the act of fetching it (ingestion), enabling sources to be catalogued before they are fully ingested and supporting scheduled synchronisation.
rest_api— paginated REST endpoint (ACLED, UCDP, IOM DTM, Global Slavery Index)csv_file— local or MinIO-stored CSV (survey exports, custom datasets)geojson_file— GeoJSON Feature Collections (georeferenced events, administrative boundaries)sqlite_file— SQLite / .db files (legacy datasets, Arkisto exports)shapefile— ESRI Shapefile (GIS datasets from national mapping agencies)wfs— OGC Web Feature Service (national mapping and cadastral agencies)sparql_endpoint— Linked Data (Wikidata, ICTY tribunal archives)
Each connector carries a field_map (source field → (CD)ISaW field) and a layer_assignments configuration declaring how source fields distribute across the five-layer schema.
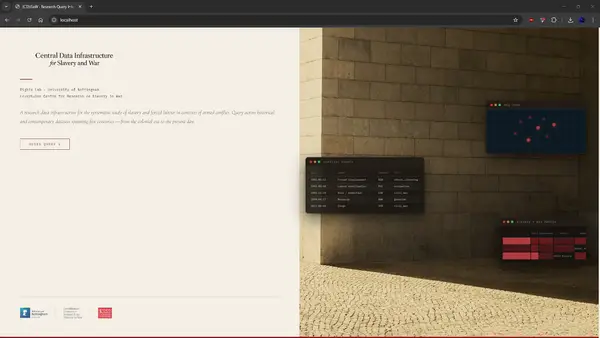
The Query Interface: A 4-Step Wizard
The web UI guides researchers through a structured 4-step wizard to build a cross-layer query, combining typological, temporal, geographic, and output-format constraints. Each step corresponds to a layer, making the query architecture transparent to the researcher.
Step 1 — Typology Selection — Researchers define their research question using the Classification Matrix. Selecting cells from both axes produces a logical intersection: “return all datasets and events matching these slavery types and these conflict contexts.” Saved CDQ queries appear in a Recent Queries panel above the matrix for one-click restoration.
Step 2 — Temporal Window — Set the date range using historical period presets (Bosnian War 1992–1995, Transatlantic Slave Trade 1600–1870) or custom from/to dates across the full corpus (1700–present).
Step 3 — Geographic Extent and Output Format — Independently controls which records are included (Global / Country / Bounding Box via PostGIS ST_Within) and how results are organised spatially (Raw Coordinates / H3 Hexagons at researcher-specified resolution 2–7 / Country Level).
Step 4 — Results — Matching records displayed across three tabs: Datasets (source cards with format, licence, record count), Conflict Events (tabular georeferenced events), and Map View (MapLibre GL rendering). From Step 4, researchers can save a persistent CDQ code or open the full-screen Dataset Explorer with H3 overlay visualisation.
CDQ Codes: Citable Query Records
CDQ (Cross-layer Data Query) codes are persistent, human-readable identifiers for specific query configurations — conceptually analogous to a DOI for a dataset, but for a query.
Format: CDQ-YYYYMMDD-XXXXX
Example: CDQ-20260314-AE7F3When a researcher saves a query, the full state — typology selections, date range, geographic extent, output format — is serialised to JSON and stored in the PostgreSQL saved_queries table. The CDQ code can be shared as a URL, cited in a publication as a reproducible reference to a specific cross-source query, or restored in a single click from the Recent Queries panel. This mechanism addresses a core reproducibility challenge in computational social science: the inability to cite not just data but the specific query logic used to derive a result.
Research Significance
The platform’s contribution is not a new dataset — it is a new relationship between existing datasets. Four research contributions underpin it:
Cross-source ontological normalisation — a reproducible, extensible framework for structuring heterogeneous evidence within a shared five-layer schema, enabling comparisons that would otherwise require bespoke data wrangling per research question.
Typology-first query design — by making the classification matrix the entry point for every query, the platform operationalises a theoretical claim: that the research question — the intersection of slavery and conflict type — is logically prior to temporal, spatial, and actor filters.
Citable query infrastructure — CDQ codes extend research reproducibility beyond dataset citation to query reproducibility, providing a mechanism for citing the specific analytical operation performed on data.
Connector-based ingestion architecture — the declarative connector system separates source description from ingestion logic, enabling new sources to be catalogued and ingested without modifying core platform code — essential for a platform designed to grow with the field’s evolving source landscape.
Future Directions
Planned extensions include GeoAnchor integration for historical place-name disambiguation, a Strawberry-based GraphQL endpoint, a full actor timeline view tracing Layer 3 entities across events and periods, Celery Beat for scheduled ACLED/UCDP synchronisation, IIIF document viewer integration for archival sources, and the StratMap-SiW Bosnia pilot dataset as the first full-scale cross-layer query demonstration.