Ask an LLM to describe a city and it will give you something that feels true. Not a list of coordinates, not an administrative boundary, but a sense of character: the industry a city is known for, its reputation, its relationship to surrounding regions, what kind of place it is often described as. This is not spatial knowledge. It is platial knowledge — the accumulated, culturally mediated understanding of what places mean, drawn from the vast corpus of text the model was trained on.
That distinction matters a great deal if you are trying to build location-aware AI systems.
LLMs Encode Culture, Not Coordinates
A language model has no GPS. It has no access to a spatial database, no concept of projection, and no direct representation of geometry at inference time. What it has is statistical patterns across billions of sentences written by people describing their world. When a model talks about a place, it is synthesising those descriptions — implicitly weighting the associations, narratives, and emotional registers that appear most repeatedly in text.
This means LLMs are surprisingly good at capturing platial knowledge: the things about places that resist formalisation in GIS. Ask about the character of a neighbourhood — its social dynamics, its reputation, its sense of transition — and a model trained on local news, forums, and personal writing will often produce something recognisable. This is not magic; it is the aggregate view of a very large number of written accounts.
It also means that LLMs reproduce every bias baked into those accounts. Well-documented places — large Western cities, tourist destinations, historically significant sites — are richly represented. Small towns, rural areas, and places that generate less written documentation are known only faintly, if at all. The model’s geography is the geography of who writes, and who is written about.
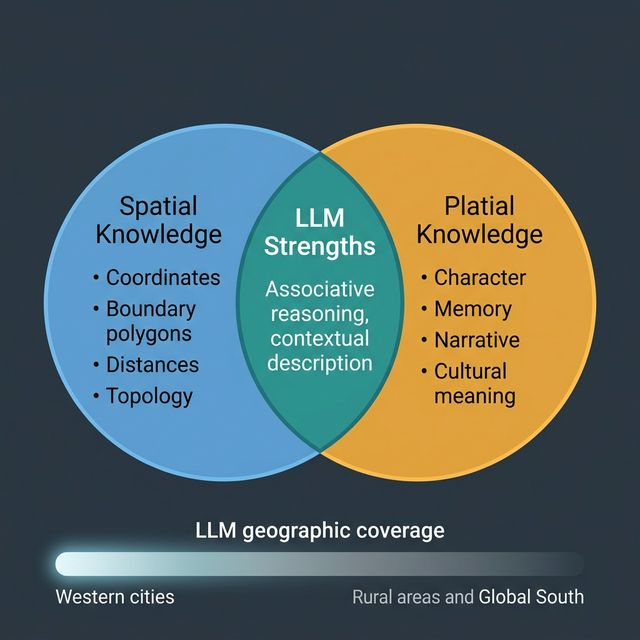
Three Things LLMs Do Well with Place
Associative character. LLMs are good at connecting places with their cultural associations: industries, events, architectural styles, regional identity, food. “What is Sheffield known for?” produces a coherent and largely accurate answer because those associations appear densely in the training corpus.
Narrative context. A model can situate a place in a story — a city’s industrial rise and decline, how a neighbourhood has changed, how a region relates to national identity. This is genuinely useful for content generation, research overviews, and contextualising spatial data for non-specialist audiences.
Cross-place reasoning. LLMs can generalise across places in ways that require cultural intuition: “places in England that feel similar to Bristol,” “how does the planning culture in Amsterdam differ from London?” These are questions that spatial data alone cannot answer — they require the kind of relational platial knowledge embedded in text.
Three Things LLMs Get Wrong
Boundaries and precise extent. LLMs handle fuzzy place names poorly when precision is required. Ask where “the Midlands” ends, or which streets fall inside a specific ward, and the model will confabulate plausibly-sounding answers that may be wrong. For boundary queries, always use a spatial database.
Recency. Training data has a cutoff. A place that has undergone significant change — a redeveloped waterfront, a demolished landmark, a newly designated area — may be described in terms that were accurate two or three years ago. LLM knowledge of place is always to some degree historical.
Under-represented geographies. The imbalance in training data is severe at the global scale. An LLM asked about peri-urban areas in the Global South, or small-town dynamics in regions with little English-language internet presence, will produce output with much lower reliability than it does for central London or Manhattan. This matters enormously for applications intended to operate across diverse geographies.
Towards Grounded Place-Aware AI
The most promising applications combine LLM platial knowledge with structured spatial data — using each for what it does well. A workflow that retrieves a neighbourhood boundary from a spatial database, enriches it with census attributes, and then asks an LLM to generate a natural-language summary that contextualises and interprets those attributes gets closer to both rigorous and human-meaningful output than either approach alone.
This is partly what motivates research into retrieval-augmented generation (RAG) for spatial contexts: grounding model output in verified, current spatial facts while preserving the model’s capacity to reason associatively and narratively. Rather than asking the LLM to assert where something is, you tell it where something is and ask it to reason about what that means.
Place has always resisted clean formalisation. LLMs, for all their limitations, have absorbed more of the messy human reality of place than any previous computational system. The task now is to use that capacity honestly — knowing what it can and cannot do, and designing systems that compensate for its gaps rather than pretending they do not exist.